
GLM-130B: AN OPEN BILINGUAL PRE-TRAINED
1 INTRODUCTION
控诉GPT-3训练过程不开源(正确的)。想做一个开源的大规模的模型,但是遇到了很多困难。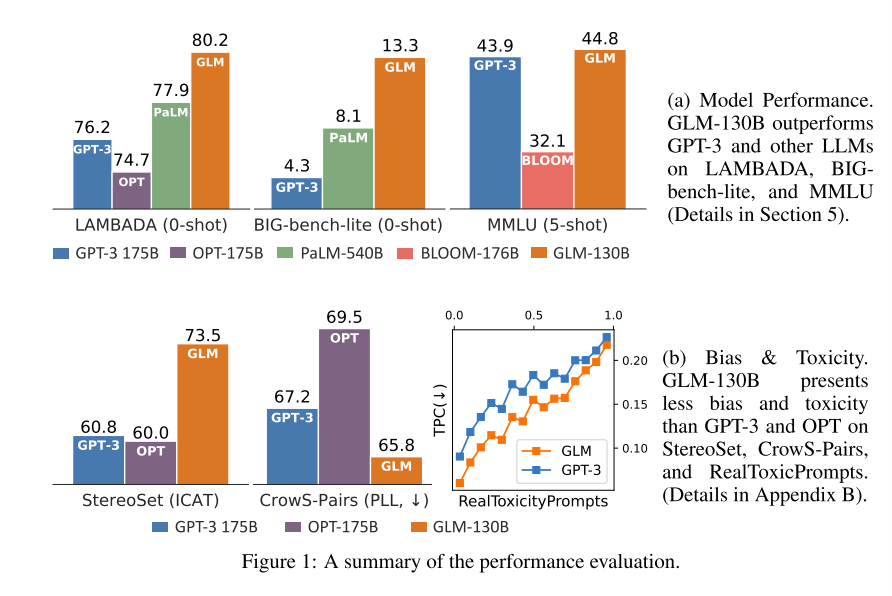
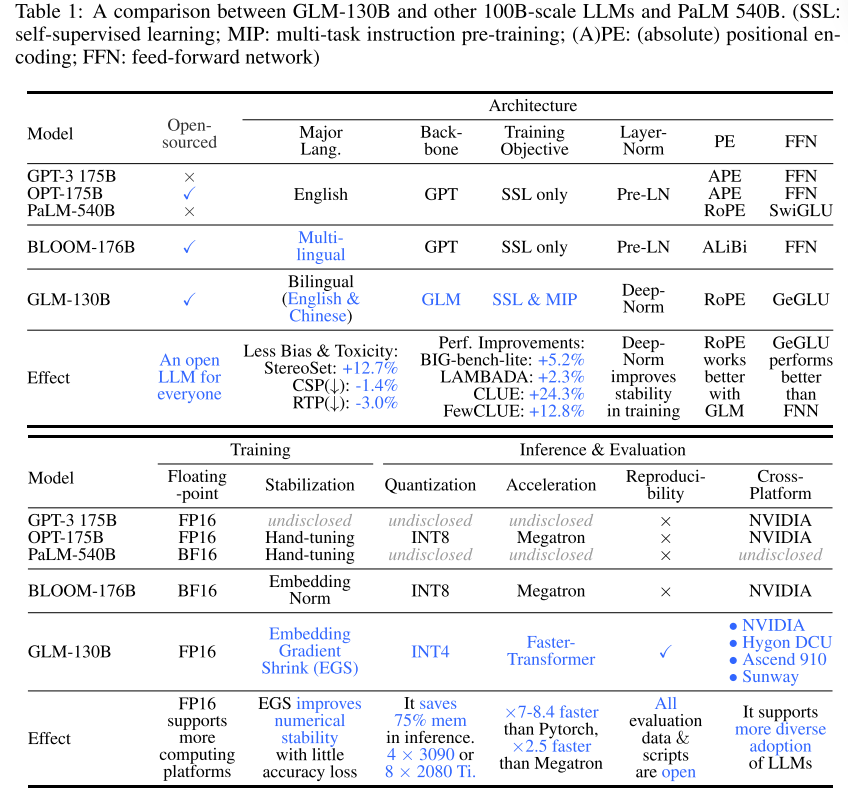
看着这表和图,glm的训练资源还是挺少的,效果也还可以。不仅仅介绍了GLM成功的训练过程,还介绍了在训练中的错误思路。训练稳定性是其中的一个难点,尝试了不同的方法后,发现嵌入梯度收缩可以稳定训练过程。
用了双向空白填充预训练方法进行训练。降低了训练资源,同时可以达到INT4量化,迄今为止,使用100B级llm所需的最实惠的GPU.
能开源的都开源了!
2 THE DESIGN CHOICES OF GLM-130B
2.1 GLM-130B’S ARCHITECTURE
GLM主要框架
不同于GPT,GLM-130B用的是GLM作为框架。GLM 是一种基于 Transformer 的语言模型,利用自回归空白填充作为其训练目标。其双向注意遮掩文本与GPT式的单向模式区分开来,为了达成一个理解一个生成的目标,建立了两个特殊的mask token:[MASK],[gMASK]。
- MASK: 句子中的空白部分,其总长度加起来等于输入的长度。
- gMASK:句子末尾有随机长度的长空白部分,并提供前缀上下文。
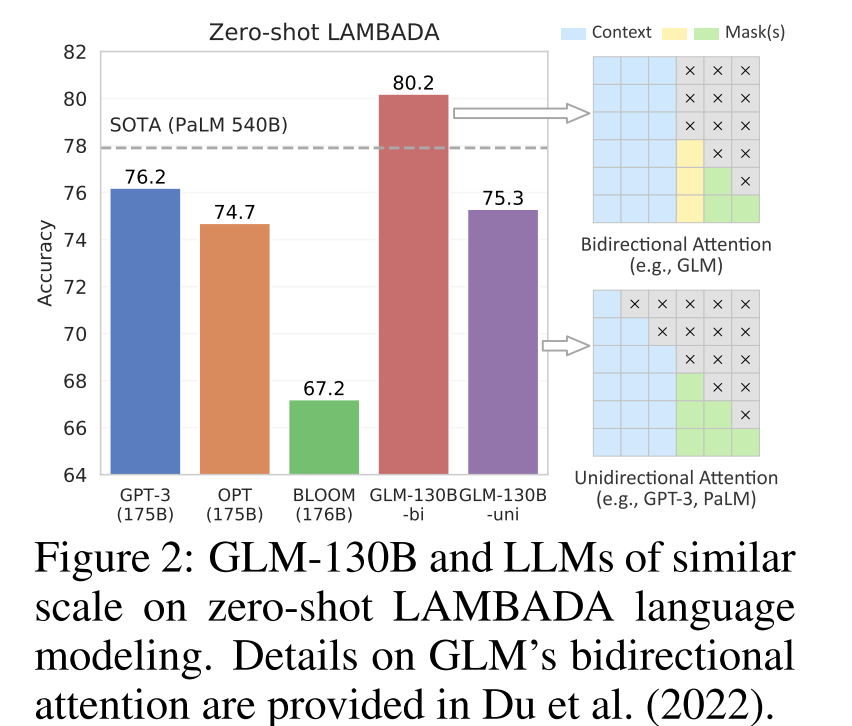
然后性能还挺好,在LAMBADA的测试集上。
Layer Normalization
如何让训练过程稳定是一个难题,选择一个合适的LN可以帮助稳定训练。尝试了了现有的Pre-LN、Post-LN、Sandwich-LN,但是不能帮助稳定训练。
然后后来研究集中在改进Post-LN上,虽然他不能稳定GLM-130B,但是他在下游任务上表现的比较好。然后在一次用最新的DeepNorm生成初始化Post-LN后,可以保证训练稳定。假定GLMN-130B的层数为N,那么:
$$DeepNorm\left ( \chi \right ) = LayerNorm\left ( \alpha \cdot \chi +Network\left ( \chi \right ) \right )$$
$$\alpha =\left ( 2N \right ) ^{\frac{1}{2} }$$
DeepNorm 是最稳定的,因为它的梯度范数小,并且在早期训练中不会出现尖峰。
Positional Encoding and FFNs
尝试了不同的positional encoding(PE)方式和Feedforward Network改进,以期获得更好训练稳定性和下游任务表现
2.2 GLM-130B’S PRE-TRAINING SETUP
Self-Supervised Blank Infilling (95% tokens).
GLM-130B 使用 [MASK] 和 [gMASK] 来完成此任务。具体来说,[MASK] 用于屏蔽 30% 的训练标记中的连续跨度以进行空白填充。跨度的长度遵循泊松分布 (λ = 3),加起来最多为输入的 15%。对于其他 70% 的标记,每个序列的前缀保留为上下文,并使用 [gMASK] 来屏蔽其余部分。屏蔽长度是从均匀分布中采样的。
Multi-Task Instruction Pre-Training (MIP, 5% tokens).
说是预训练中的多任务学习比微调表现的好,所以建议在预训练过程中添加多个提示数据集.”5% tokens” 表示模型预训练时所使用的数据中,只有其中的5%被用于进行 Multi-Task Instruction Pre-Training (MIP)。换句话说,预训练数据集中的每个标记(token)中,只有5%的标记被用于指导模型进行多任务学习。这种设置的目的是限制多任务指令对整体模型学习的影响,以避免过度依赖特定任务的指令而损害模型对其他任务的通用性能。这样的设置有助于保持模型对各种任务的广泛适应能力。
2.3 PLATFORM-AWARE PARALLEL STRATEGIES AND MODEL CONFIGURATIONS
GLM-130B 在 96 个 DGX-A100 GPU (8×40G) 服务器集群上进行训练,花了 60 天。
The 3D Parallel Strategy.
管道并行(Pipeline Parallelism):这是一种并行计算策略,它将模型划分为一系列顺序阶段,每个并行组负责处理其中的一部分。在这个上下文中,作者提到了将模型划分为顺序阶段,每个并行组负责其中的一部分。这有助于加速模型的训练过程。
PipeDream-Flush 实现:为了进一步减小由管道并行引入的“冒泡”(bubbles,即计算等待的阶段),作者采用了 PipeDream-Flush 的实现,这是 DeepSpeed 框架的一部分。PipeDream-Flush 的目的是最小化由于管道并行引入的等待时间,提高训练效率。
全局批次大小(Global Batch Size):为了减少时间和 GPU 内存的浪费,作者采用了相对较大的全局批次大小,即 4,224。全局批次大小是指模型一次性处理的总样本数量。采用较大的全局批次大小可以提高训练效率。
张量并行(Tensor Parallelism):张量并行是另一种并行计算策略,它将模型的张量参数划分为多个部分,每个部分由不同的设备进行处理。在这里,作者采用了4路(4-way)张量并行和8路(8-way)管道并行,以达到每个 GPU 达到 135 TFLOP/s 的性能。TFLOP/s 表示每秒的浮点运算次数,是衡量计算性能的一种指标。
通过结合管道并行和张量并行,并借助 PipeDream-Flush 的实现,作者实现了在相对大的全局批次大小下,高效训练 GLM-130B 模型,提高了计算性能。详细的实验结果和设置可以在附录 C.4 中找到。
GLM-130B Configurations
想让这个大模型在单卡上运行以FP16的精度运行。
- 目标和规模: GLM-130B 的目标是使100B规模的语言模型(LLM)在单个DGX-A100(40G)节点上以FP16精度运行。根据从GPT-3采用的隐藏状态维度为12,288,最终模型的参数数量不能超过130B,从而得到GLM-130B的名称。
隐藏状态(hidden state)是指在模型学习过程中模型内部保存的信息。这个隐藏状态包含了模型对输入序列的理解和学习,是模型学到的潜在特征的表示。
模型配置和平行策略: 为了最大化GPU利用率,我们根据平台及其相应的并行策略配置模型。为了避免在中间阶段由于两端的额外词嵌入导致内存利用不足,我们通过移除其中一层来平衡管道划分,使GLM-130B具有70个transformer层。
训练细节:
- 在60天的集群访问期间,我们成功地对GLM-130B进行了4000亿个标记的训练(大约分别为中文和英文的2000亿个标记),每个样本的固定序列长度为2,048。
- 对于[gMASK]训练目标,我们使用了一个2,048个标记的上下文窗口。
- 对于[MASK]和多任务目标,我们使用了一个512个标记的上下文窗口,并将四个样本连接在一起以适应2,048序列长度。
- 在前2.5%的样本上,我们将批次大小从192温暖升至4224。
- 使用了AdamW作为优化器,设置β1和β2为0.9和0.95,权重衰减值为0.1。
- 在前0.5%的样本上,我们将学习率从10^(-7)温暖升至8 × 10^(-5),然后按照10×余弦调度进行衰减。
- 使用了0.1的丢弃率,并通过梯度裁剪值为1.0进行梯度裁剪。
3 THE TRAINING STABILITY OF GLM-130B
由于计算资源的限制,需要在计算效率和训练稳定性之间进行权衡。低精度浮点格式可以提高计算效率,但同时也容易出现溢出(overflow)和下溢(underflow)错误,导致训练崩溃。
溢出和下溢错误: 低精度浮点格式容易在处理大范围数值时发生溢出或下溢,即数值超出了计算机表示的范围,或者变得太小而无法有效表示。
权衡计算效率和训练稳定性是一个关键问题,尤其是在受到计算资源限制的情况下。选择合适的浮点格式是在训练过程中保持稳定性的重要方面。
Mixed-Precision.
使用FP16进行前向(forwards)和反向(backwards)计算,同时使用FP32来处理优化器状态和主权重(optimizer states and master weights),以减少GPU内存使用并提高训练效率。GLM-130B的训练会面临频繁的损耗峰值,并且随着训练的进行,损耗峰值会越来越频繁。
“Loss spikes” 是指训练过程中损失函数(loss function)出现突然而大幅度的增加,形成明显的波峰。这种现象通常表示模型在某些训练步骤或时期上的性能突然变差,导致损失值急剧上升。
出现峰值损失的原因是不确定的。
OPT-175B试图通过手动跳过数据和调整超参数来修复;BLOOM-176B是通过嵌入规范技术实现的(Dettmers等人,2021年)。
当TRANSFORMER规模增大的时候会出现下面几个问题。
在使用 Pre-Layer Normalization(Pre-LN)时,深层的 Transformer 主干分支的数值规模(value scale)可能会变得极大。为了解决这个问题,GLM-130B 使用了基于 DeepNorm 的 Post-Layer Normalization(Post-LN)(参见第2.1节),这使得数值规模始终保持在可控范围内。
随着模型规模的增大,注意力机制分数增长的很快,超出了FP16的范围。有几个方法可以用,但是有利弊,都不算很好的解决问题。
Embedding Layer Gradient Shrink (EGS).
我们的实证研究表明,梯度范数可以作为训练崩溃的信息指标。具体来说,我们发现训练崩溃通常滞后于梯度范数的“尖峰”几个训练步骤。这种尖峰通常是由嵌入层的异常梯度引起的。
(但是没办法下断点)。
梯度范数是指梯度向量的长度,表示函数在某一点的变化率或斜率。在深度学习中,梯度是损失函数相对于模型参数的偏导数。梯度向量包含了每个参数方向上的变化率信息。
梯度范数通常通过计算梯度向量中所有元素的平方和的平方根来得到。对于一个参数向量 θ,其梯度 ∇J(θ) 的范数 ‖∇J(θ)‖ 可以表示为:
$$\lVert \nabla J(\theta) \rVert = \sqrt{\sum_{i=1}^{n} \left(\frac{\partial J}{\partial \theta_i}\right)^2}$$
其中 n 是参数向量的维度,(∂J/∂θ_i) 是损失函数 J 相对于第 i 个参数 θ_i 的偏导数。
梯度范数的大小反映了在当前参数值下,损失函数的变化率。较大的梯度范数表示函数在该点的变化较大,而较小的梯度范数表示函数的变化较小。在训练深度学习模型时,梯度范数的大小对于调整学习率、防止梯度爆炸等都具有重要的影响。
最后找到发现嵌入层的梯度收缩可以帮助克服损失峰值,从而稳定GLM-130B训练。
首次应用在多模态 Transformer 模型 CogView 中。具体而言,假设 α 是收缩因子,该策略可以通过以下简单的实现来达到:word_embedding = word_embedding * α + word_embedding.detach() * (1 - α)。图4(b)的实验结果表明,经验上设置 α = 0.1 能够有效减小大多数可能出现的”spikes”,而且速度损失微乎其微。
4 GLM-130B INFERENCE ON RTX 2080 TI
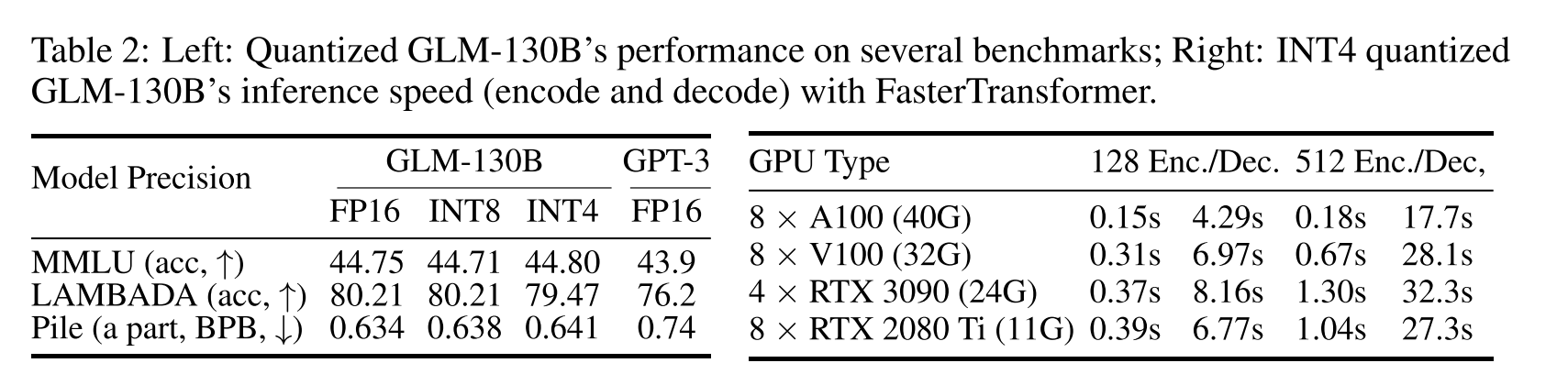
如何降低硬件要求,不降低效率。也尝试了用C++重构GLM,比用PyTorch的实现要快7-8倍。
INT4 Quantization for RTX 3090s/2080s.
在OPT-175B and BLOOM-176B中,将模型权重和激活量化为INT8后,可能包涵极端的离群值,但是这个值影响很小,可以对通过矩阵乘法分解来解决异常值。
但是在GLM中大概有30%,于是专注模型权重的量化,同时保持激活的 FP16 精度。我们简单地使用训练后的absmax量化,权重在运行时动态转换为FP16精度,引入了少量的计算开销,但大大减少了存储模型权重的GPU内存使用量。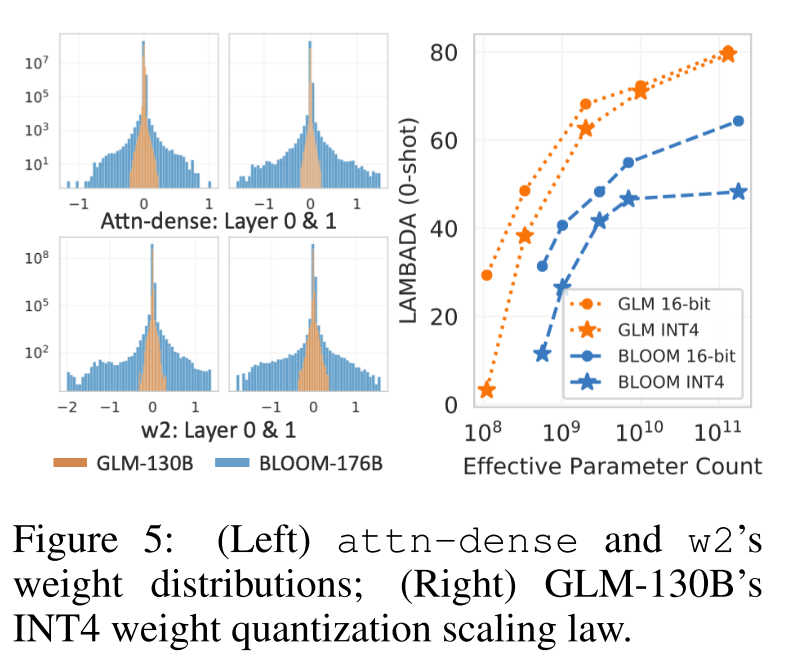
GLM’s INT4Weight Quantization Scaling Law.
发现GLM的INT4权重量化出现了缩放规律,然后只在GLM中发现了这个情况。
Wider-distributed Linear Layer(宽分布的线性层):
当模型中的线性层分布较宽时,可能涉及到更多的神经元或权重。这可能发生在某些层(例如自注意力层)中,这里提到的是 “w2 matrices” 和 “attn-dense”,这可能是与注意力机制相关的权重矩阵。
Quantization with Larger Bins(使用更大的量化间隔进行量化):
量化是将浮点数表示的权重和激活值转换为较少位数的整数,以减少模型的存储需求和计算成本。然而,在宽分布的线性层中,为了保持模型性能,可能需要使用更大的量化间隔(larger bins)。这意味着将一定范围内的浮点数映射到同一个整数值,导致量化的精度损失。
Precision Loss(精度损失):
当使用更大的量化间隔时,模型的权重和激活值的精度会降低。这可能会影响模型的性能,尤其是在对精度要求较高的任务中。
INT4 Quantization Failure for GPT-style BLOOM(GPT风格的BLOOM使用INT4量化失败):
文本中提到的 INT4 可能是指使用 4 位整数进行量化。由于线性层的宽分布,使用较低位数进行量化可能导致性能问题,因此可能出现 INT4 量化失败的情况。
GLMs 在神经元激活或权重的取值范围上具有更紧凑的分布,与 GPTs 相比,变化幅度较小。
缩小的差距可能意味着在更大规模的 GLM 模型中,使用较低位数的整数进行量化(INT4)与使用更高位数的浮点数进行量化(FP16)之间的性能差异减小。
5 THE RESULTS
根据自己的准则选取了GLM-130B的数据集:
English: 1) For tasks with fixed labels (e.g., natural language inference): no datasets in such tasks
should be evaluated on; 2) For tasks without fixed labels (e.g., (multiple-choice) QA, topic classi-
fication): only datasets with an obvious domain transfer from those in MIP should be considered.Chinese: All datasets can be evaluated as there exists a zero-shot cross-lingual transfer.
5.1 LANGUAGE MODELING
在Pile和LAMBADA上进行测试,结果都还可以。
5.2 MASSIVE MULTITASK LANGUAGE UNDERSTANDING (MMLU)
MMLU(Hendrycks et al., 2021)是一个多样化的基准,包括 57 个涉及人类知识的多项选择问答任务,范围从高中水平到专家水平。然后把一些LLM同GLM一起进行测试: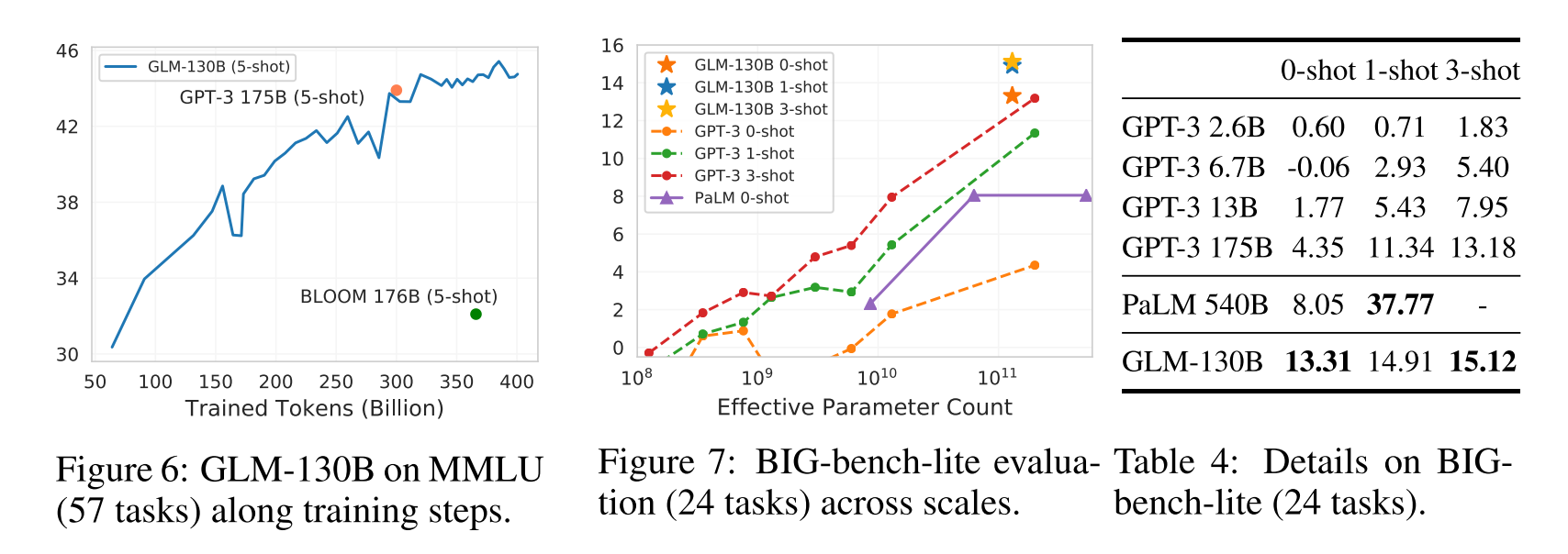
5.3 BEYOND THE IMITATION GAME BENCHMARK (BIG-BENCH)直接翻译
大板凳(Srivastava等人,2022)对具有挑战性的任务进行基准测试,这些任务涉及模型的推理能力、知识和常识。考虑到评估它的150个任务对llm来说是很耗时的,我们现在报告了大板凳-精简-一个官方的24个任务的分集。从图7和表4可以看出,在零拍设置上,GLM-130B的表现优于GPT-3 175B,甚至比PaLM 540B大4倍。这可能是由于GLM-130B的双向上下文注意和MIP,这已被证明可以改善看不见的任务中的zero-shot结果(Wei等人,2022a;Sanh等人,2022)。随着镜头数量的增加,GLM-130B的性能不断上升,保持了其优于GPT-3的性能(参见附录D.3和表13,每个模型和任务的详细信息)。
限制和讨论。在上面的实验中,我们观察到GLM-130B的性能增长(13.31 ~ 15.12)随着少炮样本量的增加,不如GPT-3的性能增长(4.35 ~ 13.18)显著。下面是我们对这一现象的直观理解。首先,GLM-130B的双向特性可能会导致较强的零拍性能(如零拍语言建模中所示),从而在类似尺度(即100b尺度)的模型上比单向llm更接近少拍“上限”。其次,这也可能归因于现有的MIP范式的不足(Wei et al., 2022a;它只涉及到训练中的零杆预测,可能会使GLM-130B偏向于更强的零杆学习,但相对较弱的背景下的少杆性能。为了纠正偏差,我们提出的一个潜在的解决方案是,如果我们有机会继续对GLM-130B进行预训练,我们将使用MIP与上下文样本的不同镜头,而不是仅使用零镜头样本。最后,尽管与GPT-3几乎相同的GPT架构,PaLM 540B的相对增长与少量的上下文学习在本质上比GPT-3更重要。我们推测,这种性能增长的进一步加速是PaLM高质量和多样化的私人收集的培训语料库的来源。通过将我们的经验与(Hoffmann et al., 2022)的见解相结合,我们逐渐认识到,应该进一步投资更好的架构、更好的数据和更多的FLOPS培训。
5.4 CHINESE LANGUAGE UNDERSTANDING EVALUATION (CLUE)直接翻译
我们在已建立的中国NLP基准CLUE (Xu et al., 2020)和FewCLUE (Xu et al., 2021)上评估了GLM-130B在中国的zero-shot性能。请注意,我们在MIP中不包括任何中国下游任务。到目前为止,我们已经完成了两个基准测试的部分测试,包括7个CLUE和5个FewCLUE数据集(参见附录D.6)。我们将GLM-130B模型与现有最大的中国单语语言模型- 260B ERNIE Titan 3.0模型(Wang et al., 2021)进行了比较。我们按照它的设置报告开发数据集上的零命中率结果。在12个任务中,GLM-130B的表现始终优于ERNIE Titan 3.0(参见图8)。有趣的是,在两个抽象MRC数据集(DRCD和CMRC2018)上,GLM-130B的表现至少比ERNIE好260%,这可能是因为GLM-130B的训练前目标与抽象MRC的形式自然产生了共振。
6 RELATED WORK直翻
Pre-Training
普通语言建模是指仅解码器的自回归模型(例如 GPT(Radford 等人,2018)),但它也识别文本上任何形式的自我监督目标。最近,基于 Transformer(Vaswani 等人,2017)的语言模型呈现出令人着迷的缩放定律:随着模型规模的扩大,新的能力(Wei 等人,2022b)会出现,从 1.5B(Radford 等人,2019)到 10B - 规模语言模型(Raffel et al., 2020;Shoeybi et al., 2019;Black et al., 2022),到 100Bscale GPT-3(Brown et al., 2020)。后来,尽管出现了许多100B级的LLM(Lieber et al., 2021; Thoppilan et al., 2022; Rae et al., 2021; Smith et al., 2022; Chowdhery et al., 2022; Wu et al., 2021;Zeng 等人,2021;Wang 等人,2021)有英文和中文版本,但它们不向公众开放或只能通过有限的 API 访问。LLM的封闭性严重阻碍了其发展。 GLM-130B 的努力以及最近的 ElutherAI、OPT-175B(Zhang 等人,2022)和 BLOOM176B(Scao 等人,2022)旨在为我们的社区提供高质量的开源LLM。 GLM-130B 与其他产品的另一个不同之处在于,GLM-130B 注重LLM对所有研究人员和开发人员的包容性。从我们对其尺寸的决定、架构的选择以及在普及的 GPU 上进行快速推理的支出来看,GLM-130B 相信,所有这些的包容性是实现LLM向人们承诺的福利的关键。
Transferring
虽然微调已经成为一种事实上的迁移学习方式,但由于其巨大的规模,llm的迁移学习一直专注于提示和上下文学习(Brown et al., 2020;刘等,2021a)。在此工作中,我们的评价也在这样的背景下。然而,最近的一些尝试已经在语言模型的参数高效学习(Houlsby等人,2019)和提示调优(即p调优,Li & Liang (2021);Liu等人(2021c);Lester等人(2021年);Liu等人(2022))。在本工作中,我们不关注它们,将其在GLM-130B上的检测留在未来的研究中。
Inference.
如今,大多数公众可访问的llm都通过有限的api提供服务。在这项工作中,我们努力的一个重要部分是llm的高效和快速推理。相关工作可能包括蒸馏(Sanh等人,2019;焦等,2020;Wang et al., 2020),量化(Zafrir et al., 2019;沈等人,2020;Tao等人,2022),以及剪枝(Michel等人,2019;范等,2019)。最近的工作(Dettmers等人,2022年)表明,由于异常维数的特殊分布,llm(如OPT-175B和BLOOM-176B)可以量化为8位。然而,在这项工作中,根据我们对LLM架构选择的新见解,我们证明了GLM对INT4权重量化的标度定律。这样的量化,加上我们在将GLM-130B应用到FasterTransformer上的工程努力,使得GLM-130B可以在很少的4×RTX 3090 (24G) gpu或8×GTX 1080 Ti (11G) gpu上有效地进行推理。它实现了llm对公众的经济可用性,并逐步实现了我们对llm包容性的承诺。