
AN OVERVIEW ON LANGUAGE MODELS:RECENT DEVELOPMENTS AND OUTLOOK
介绍
从五个角度对其进行研究:1)语言单元、2)结构、3)训练方法、4)评估方法和 5)应用。最后,我们指出了未来的几个研究方向。
2 模型类型
CLM 通常指的是自回归模型,该模型在给定前面的上下文的情况下预测下一个语言单元
2.1 结构LM Structural LM
结构语言模型 不是按顺序或反向顺序预测语言单元,而是基于预定义的语言结构(例如依存树或成分解析树)来预测语言单元.(如副词,动词,连词)
2.2 双向LM Bidiredctional LM
双向 LM 不使用因果上下文进行预测,而是利用来自两个方向的上下文、MLM
2.3 置换LM Permutation LM
利用了 CLM 和屏蔽 LM。给定语言单元的输入序列,排列 LM 随机化输入语言单元的顺序并构造输入序列的不同排列。
3 语言单位 Linguistic Units
为了估计文本序列的概率,LMs将文本序列分割成小的语言单位,如字符、单词、短语或句子。这个过程称为标记化。不同的语言和模型可能有不同的适当的标记化方法。这里,我们以英语为例。在本节中,我们将根据单元大小检查语言建模中使用的典型标记化方法。
3.1 字符 Characters
使用字符的词汇量要小得多,从而导致离散空间和模型大小更小
3.2 字词 Words and Subwords
研究人员赞成将字典中没有出现的单词分解为子词。这为 OOV (Out-Of-Vocabulary)问题提供了灵活有效的解决方案 [39, 40]。开发了几种子词分割算法来提高语言模型的性能。
3.2.1 Statistics-based Subword Tokenizers
- Byte Pair Encoding (BPE):
BPE [41] 是一种简单的数据压缩技术,它递归地用单个未使用的字节替换序列中最常见的字节对 - WordPiece
如果 A 和 B 对在每个迭代步骤中具有最高分数 P(AB)/P(A)P(B)(而不是最高频率 P(AB)),则 WordPiece 会合并 A 和 B 对。
#### 3.2.2 Linguistics-based Subword Tokenizers
基于语言学的子词分词器利用语言知识并将单词分解为更小的语法单元,例如语素或音节.
3.3 短语 Phrases
由于不同的上下文和固定搭配,单个单词的语义可能会产生歧义.由于短语提供的音素序列比其组成部分更长,因此它们对于 ASR 识别错误更加稳健。
### 3.4 句子级Sentences
句子级语言模型避免使用链式法则。他们生成句子特征,然后直接对句子概率进行建模。
这是因为直接对句子概率进行建模比式(1)中的建模更方便。
## 4 模型结构 Model Structures
4.1 N-gram Models
N-gram lm不是使用所有的历史语境,而是只使用之前的N-1语言单位来预测当前的语境;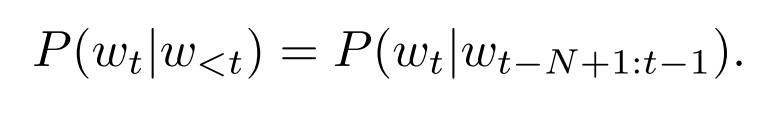
如果在训练语料库中从未看到某个特定的词组合(N-gram),则该N-gram的概率为零。这意味着如果模型遇到这个未见过的N-gram,它将无法为下一个词提供任何概率信息。
分母为零问题:在N-gram语言模型中,概率通常通过使用N-1个先前词的组合作为分母来计算。如果这个(N-1)-gram从未在训练数据中出现,那么分母将为零,导致无法计算任何词的概率。
例如,考虑一个三元语言模型(3-gram),其中每个词的概率取决于前两个词。如果训练数据中从未包含某个特定的三个词的组合,那么模型将无法为第三个词提供任何概率。这种情况下,模型会对未见过的词组合产生零概率。
平滑技术的引入:为了解决这些稀疏性问题,引入了平滑技术,其中一种简单的方法是加法平滑。该方法通过为每个N-gram的计数添加一个小的常数值,防止概率计算中出现零,从而避免了上述问题。
更高效的方法为back-off和interpolation。
4.2 Maximum Entropy Models
最大熵模型是一种用于估计文本序列概率的模型,也被称为指数模型。这种模型的目标是在给定一些约束条件下,选择概率分布中的最不确定性,即最大熵的分布。
4.3 Feed-forward Neural Network (FNN) Models
神经语言模型采用连续嵌入空间(单词的分布式表示)来克服数据稀疏问题。前馈神经网络(FNN)LM [7,72,73,74]是早期的神经网络模型之一。
FNN LM通过将单词投影到连续空间具有几个优势。首先,它可以通过将每个单词表示为具有密集向量空间的N-gram来处理未见的N-grams。其次,它在存储效率上更具优势,因为不需要计数和存储传统N-gram模型的转移概率。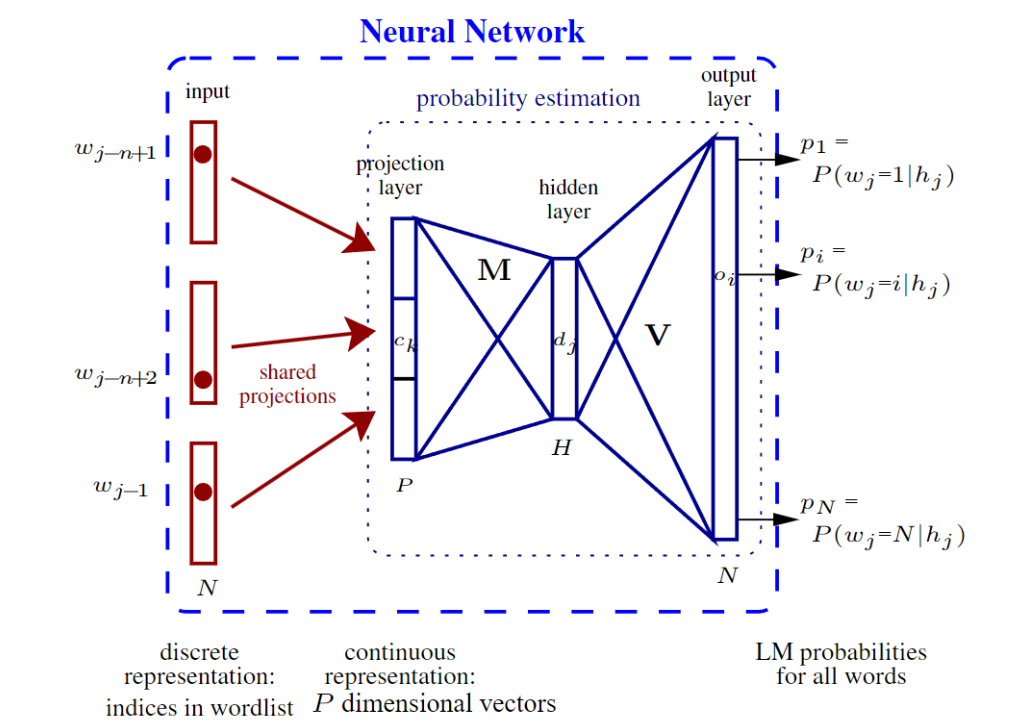
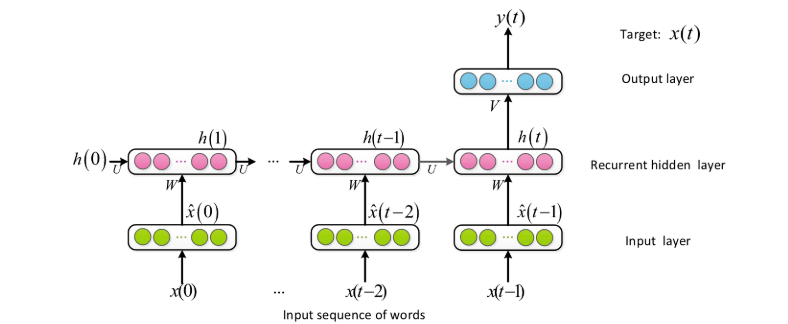
### 4.4 Recurrent Neural Network (RNN) Models
用固定长度的历史语境来预测下一个单词显然是不够的。与N-gram和FNN LMs中使用的有限历史背景相比,循环神经网络LMs[8,75,76,77,78]可以利用任意长的历史来预测下一个单词
尽管RNN LMs在理论上可以利用全部历史信息进行预测,但由于梯度消失问题,实际上它们通常只能有效地利用附近的上下文。与之相比,基于Transformer的LMs具有自注意力机制,可以更好地处理长距离的依赖关系,使其在一些任务上表现更为出色。
4.5 Transformers
Transformer有三个主要变体:编码器(encoder-only)、解码器(decoder-only)和编码器-解码器(encoder-decoder)。编码器模型可以访问输入的所有位置,并利用双向上下文来预测词,适用于需要理解完整句子的任务,如文本分类。解码器模型只能使用前面的单词来预测当前单词(即,自回归模型),适用于文本生成任务,如故事生成。编码器-解码器模型在编码阶段可以访问所有词,在解码阶段可以访问当前词之前的词,适用于序列到序列的任务,如翻译和摘要生成。
![]()
5 Pre-trained Language Models
5.1 Pre-training
三种预训练模型:MLM,Fine-tuning,prompt-based fine-tuning (or
prompt-tuning)。
MLM通过MASK掉单词通过上下文进行预测,Fine-tuning通过贴标签,rompt-based fine-tuning (or
prompt-tuning)通过提供提示或示例来引导模型的行为。它涉及在与目标任务相关的一组示例或提示上对模型进行训练。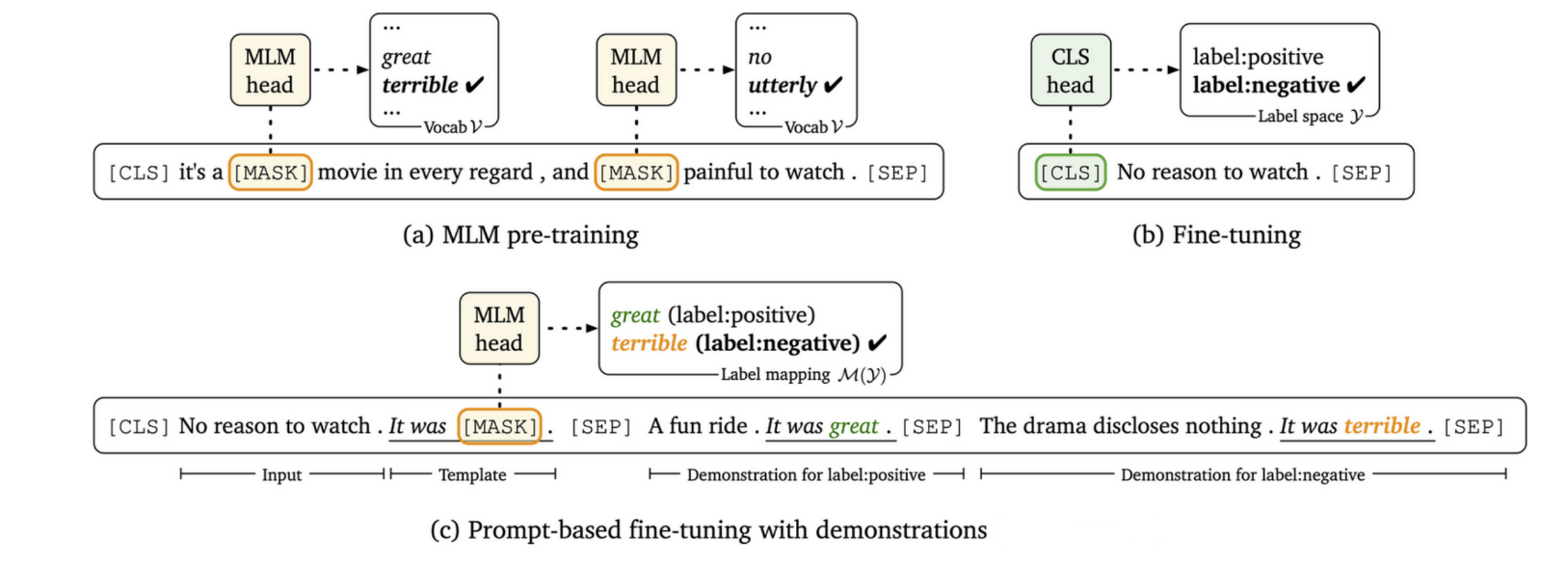
### 5.2 Fine-Tuning and Prompt-Tuning
预训练语言模型(PLMs)在预训练阶段学习非任务特定的语言知识,而微调则执行模型的任务特定适应,使其可以应用于不同的下游任务。
## 6 Model Evaluation
LM 评估有两种类型:内在评估和外在评估。内在评估检查 LM 的内部属性,而外在评估则研究其在下游任务中的表现。
6.1 Intrinsic Evaluation
自回归LM评估:
* 困惑度(Perplexity):困惑度是用于评估语言模型性能的常见指标。对于给定的测试文本序列,困惑度(PPL)被定义为该序列的倒数,除以该序列中的单词数。
双向LM评估:
* The pseudo-log-likelihood score(PLL)
* the pseudo-Perplexity (PPPL)
### 6.2 Extrinsic Evaluation
GLUE和SuperGLUE
6.3 Relation between Intrinsic and Extrinsic Evaluations
看看两个东西之间有什么相关连的,经过实验和理论证明,在一定条件下,他们之间存在相关性。
7 Applications in Text Generation
语言模型最重要的应用之一是文本生成,其目的是根据输入数据生成单词序列。
* 自动语音识别
* 机器翻译
* 故事生成
在本节中,我们将介绍文本生成中使用的常用技术,然后解释如何将语言模型应用到每个代表性任务中。
### 7.1 Decoding Methods
解码是指决定下一个输出语言单位以生成文本的过程。
1. Maximization-based decoding
* Decoding Objective (解码目标): 文中提到的解码目标是基于最大化概率的方法。假设模型将更接近人类生成的真实文本的高质量文本赋予更高的概率,最大化概率的解码策略会寻找具有最高概率的标记(tokens)作为生成的文本。
Greedy Search (贪婪搜索): 贪婪搜索是一种解码策略,它在每个步骤选择具有最高概率的标记作为生成文本的下一个标记。这种方法简单直接,但可能导致局部最优解,因为它在每个步骤上都做出当前最优的选择。
Beam Search (束搜索): 束搜索是另一种解码策略,它在每个时间步保留一定数量的最有可能的标记,并最终选择整体概率最高的生成标记序列。相比于贪婪搜索,束搜索考虑了多个备选标记,有助于避免错过一些合理但概率较低的标记。
Trainable Decoding Algorithms (可训练解码算法): 最近提出了可训练的解码算法,其中文中提到的例子是可训练的贪婪解码。这种方法使用强化学习(reinforcement learning)来寻找最大化解码目标的翻译,它作为神经机器翻译解码器的一部分。通过训练,模型可以学到更复杂的生成策略,以便更好地满足特定的解码目标。
- Sampling-based decoding
Sampling-Based Decoding (基于采样的解码): 这是一种解码策略,它从一组采样的标记中选择下一个标记。与基于最大化概率的解码方法相比,采样-based解码通过随机采样增加了生成文本的多样性。这有助于避免最大化概率方法可能面临的问题,如生成过于重复的文本。
Issues with Maximization-Based Decoding (基于最大化概率的解码存在的问题): 基于最大化概率的解码方法很大程度上依赖于底层模型的概率,可能在生成中出现重复的问题。这种重复可能导致生成的文本缺乏多样性。
Sampling for Diversity (采样增加多样性): 采样-based解码通过随机采样提高了生成文本的多样性。然而,简单的纯采样可能会选择概率较低的标记(来自不可靠的尾部分布),导致生成的文本与前缀无关,可能变得不连贯且无意义。
Top-k Sampling and Nucleus Sampling (Top-k采样和Nucleus采样): 为了解决纯采样可能选择低概率标记的问题,最近提出了一些方法,包括Top-k采样和Nucleus采样。这两种方法从截断的语言模型分布中进行采样,即从最有可能的标记中进行采样,以避免选择概率较低的标记。
Diverse Beam Search (多样性束搜索): 文中还提到了Diverse Beam Search,它是一种可训练的基于采样的方法。这种方法旨在通过训练来提高生成文本的多样性。通过这种方式,模型可以学到在生成过程中保持一定多样性的策略。
7.2 Dialogue Systems
对话系统旨在模拟与人类用户交谈时的人类反应。对话系统可以分为面向任务的系统和开放域系统。前者专为特定任务而设计,例如在线购物的客户服务。后者也称为聊天机器人。大多数现代对话系统都是生成式语言模型的
7.3 Automatic Speech Recognition
将原始音频输入转换为相应的文本序列。
7.4 Machine Translation
于 Transformer 的模型在机器翻译方面取得了巨大的成功。
成功了多少我也不知道。
7.5 Detection of Generated texts
随着 LM 的性能越来越接近甚至超越人类,LM 的滥用(例如虚假新闻和虚假产品评论生成)已成为一个严重的问题。检测机器生成文本的能力非常重要。检测问题有两种类型:1)人工编写与机器生成,2)不真实与真实。
8 Efficient Models
如何通过较小的训练资源训练出好的模型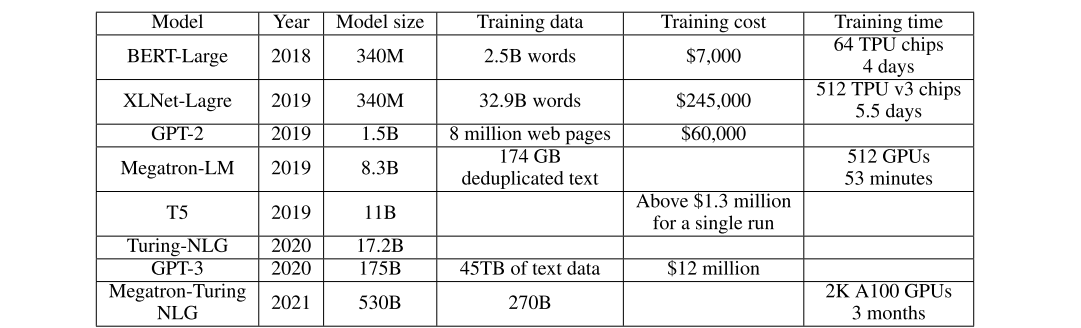
### 8.1 Data Usage
* Pre-training Data Size.
由图可知,这个在1M到1B之间提升比较大,再往后就没必要了。
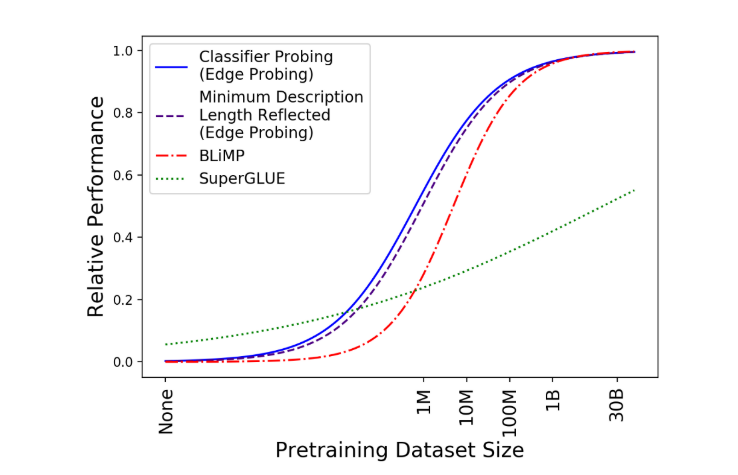
其中分类器探测测量句法和语义特征的质量,最小描述长度探测量化这些特征的可访问性,BLiMP曲线测量模型对各种句法现象的知识,superGLUE测量处理NLU任务的能力。
- Efficient Pre-Training.
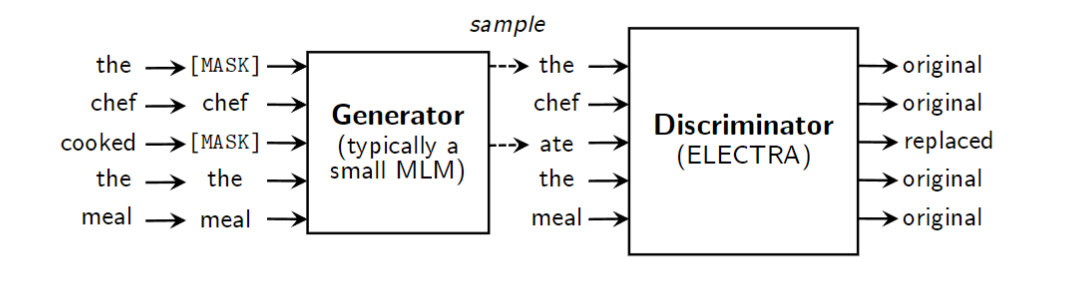
使用“替换令牌检测”(而不是“屏蔽令牌预测”)作为预训练任务。如图 11 所示,训练生成器来执行屏蔽 LM 并预测屏蔽标记。然后,主模型充当鉴别器,称为 ELECTRA,它学习决定原始或替换的标记。
BERT(MLM): 在BERT中,一个固定的百分比的标记被掩蔽,然后模型被要求预测这些被掩蔽的标记。这导致了只有一小部分标记用于训练,因此可能需要更多的计算资源和时间来达到良好的性能。
ELECTRA: ELECTRA的预训练任务是替换标记检测,其中一个生成器模型生成被替换的标记,而另一个鉴别器模型则负责判断标记是原始的还是替换的。这使得所有标记都能参与训练,从而提高了数据利用效率。
- Bridging Pre-training and Downstream Tasks.
及时的单词微调,模板(例如“It was”)及其预期的文本响应(例如“great”和“terrible”)用于提示调整。这样,预训练和提示调整共享相同的“单词预测”目标。
8.2 Model Size
压缩模型大小,为了方便部署在边缘设备上。包括:Examples include model pruning , knowledge distillation ,
low rank matrix approximation , and parameter sharing .
## 9 Future Research Directions
9.1 Integration of LMs and KGs
Knowledge Graph (KG) provides a structured representation of human knowledge .
用KG来训练LM,允许更小的模型大小,提高可解释性。
9.2 Incremental Learning
增量学习旨在融入新信息,而无需完全重新训练现有模型。
模型已经学到的信息在使用新信息进行训练时可能会逐渐忘记。
知识图谱很容易通过添加或删除事实三元组来向现有数据库添加新数据(或从中删除旧数据)[154]。显然,KG 中的当前信息不会被新收集的数据覆盖。
9.3 Lightweight Models
轻量化模型,减少模型大小和训练数据量以达到相同的效果
9.4 Universal versus Domain-Specific Models
特定领域的模型训练,仅需要较少的训练和推理工作。
9.5 Interpretable Models
LM本质还是黑盒子,缺乏数学透明度,为了解决这个问题,
提出了一个从头构建KGs模型的方法。KG 可以为每个预测提供逻辑路径,以便 LM 提供的预测更具可解释性。
9.6 Machine Generated Text Detection
开发有效的工具来识别生成式语言模型的恶意使用对于我们的社会至关重要。
10 Conclusion
本文全面概述了 CLM 及其后继者 PLM,并涵盖了广泛的主题。首先,介绍了不同级别的语言单元,并研究了如何使用语言单元预测来训练语言模型。其次,讨论了语言模型采用的标记化方法。第三,回顾了 PLM 的语言模型结构和训练范式。第四,研究了语言模型的评估和应用。特别是,详细介绍了文本生成方面的几个应用。最后指出了未来的几个研究方向。强调了对可解释、可靠、特定领域和轻量级语言模型的需求。