
AN OVERVIEW ON LANGUAGE MODELS: RECENT DEVELOPMENTS AND OUTLOOK
Chengwei Wei1, Yun-Cheng Wang1, Bin Wang2, and C.-C. Jay Kuo1
1University of Southern California, Los Angeles, California, USA
2National University of Singapore, Singapore
chengwei@usc.edu
・"For this next step of my blog let me compare the population of California
and Alaska"
・"Ok let's get both of their populations"
・"I know that I am very likely to not know these facts off the top of my head,
let me look it up"
・"[uses Wikipedia] Ok California is 39.2M"
・"[uses Wikipedia] Ok Alaska is 0.74M"
・"Now we should divide one by the other. This is a kind of problem I'm not going
to be able to get from the top of my head. Let me use a calculator"
・"[uses calculator] 39.2 / 0.74 = 53"
・"(reflects) Quick sanity check: 53 sounds like a reasonable result, I can continue."
・"Ok I think I have all I need"
・"[writes] California has 53X times greater..."
・"(retry) Uh a bit phrasing, delete, [writes] California's population is 53 times
that of Alaska."
・"(reflects) I'm happy with this, next."
"California's population is 53 times that of Alaska."
Human text generation vs. LLM text generation
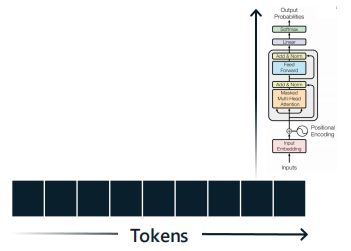
深度学习模型在处理文本数据时需要将文本分解成可理解的单元,以便进行各种文本相关的任务。模型需要通过这些单元来思考、分析和做出决策。
Structural LM
Bidirectional LM
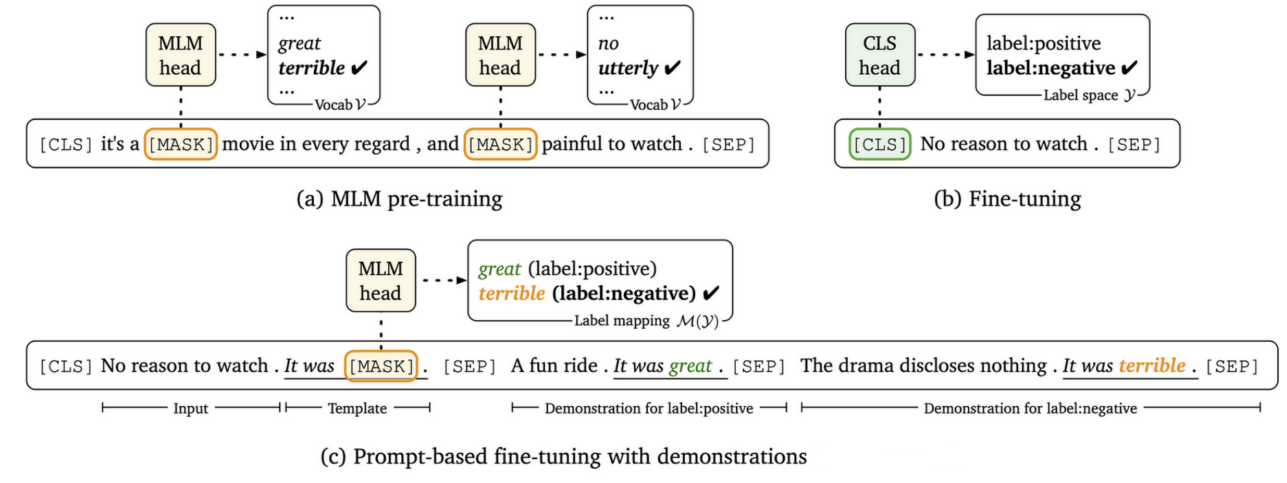
它们用来理解句子中的词语之间的关系。有时候,句子中的某个词会被替换成一个特殊的符号 [MASK],这样句子就不完整了。这种模型的目标是通过大量没有标记的文本来学习语言的含义。
不同于其他语言模型,这种模型不是用来生成文本,而是作为一种基础模型,可以在后续的任务中进行微调,以帮助我们更好地理解语言和处理各种不同的问题。简单来说,它们帮助我们了解句子中词语之间的关系,并且可以用来做更多的工作
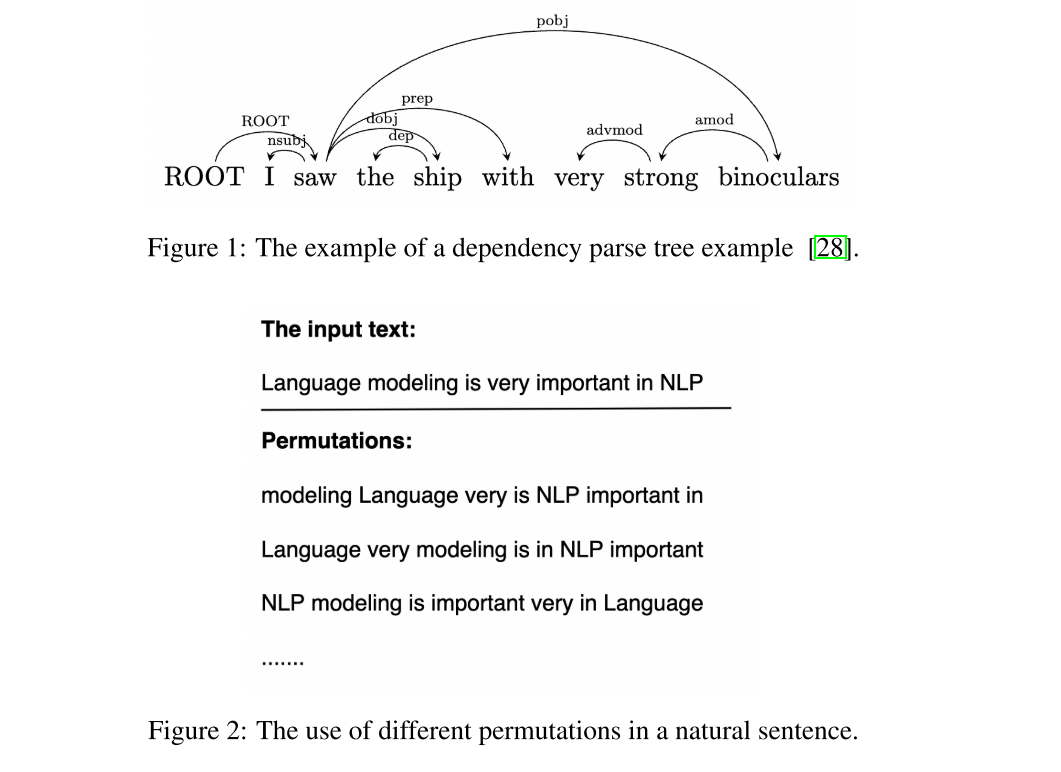
Permutation LM
有两种不同的语言模型,一种叫做 "masked LM",另一种叫做 "CLM"。它们各自有好处和不足之处。"masked LM" 需要使用一些特殊标记,比如 [mask],但这些标记在实际应用中并不会出现。而 "CLM" 只考虑文本的前面部分内容。
另外还有一种新型模型,叫做 "permutation LM"。它结合了 "CLM" 和 "masked LM" 的优点。这个模型的工作方式是,给定一组词语,它会随机改变词语的顺序,就像把单词的排列方式打乱一样。然后它会根据不同的排列方式来预测下一个词语是什么。
Statistics-based Subword Tokenizers
它们会找出文本中经常出现的一些字母组合,然后用一个新的符号(就像是一个新词)来代替这些字母组合。这个新符号在原来的文本中是不存在的,但它可以帮助我们用更少的字节来表示相同的信息。
举个例子,假设原来的文本中有很多次出现了 "ing" 这个字母组合,这个工具可以把它替换成一个新的符号,比如说 "$",这样文本就变得更短了。但是,使用这个新符号仍然可以准确地传达相同的信息。这对于在计算机中存储和传输大量文本信息时非常有用。
Byte Pair Encoding (BPE)

P(AB)/P(A)P(B) (rather than the highest frequency P(AB)) at each iterative step. For example, WordPiece merges the pair of “u” and “g” in Fig.3_______________________WordPiece.
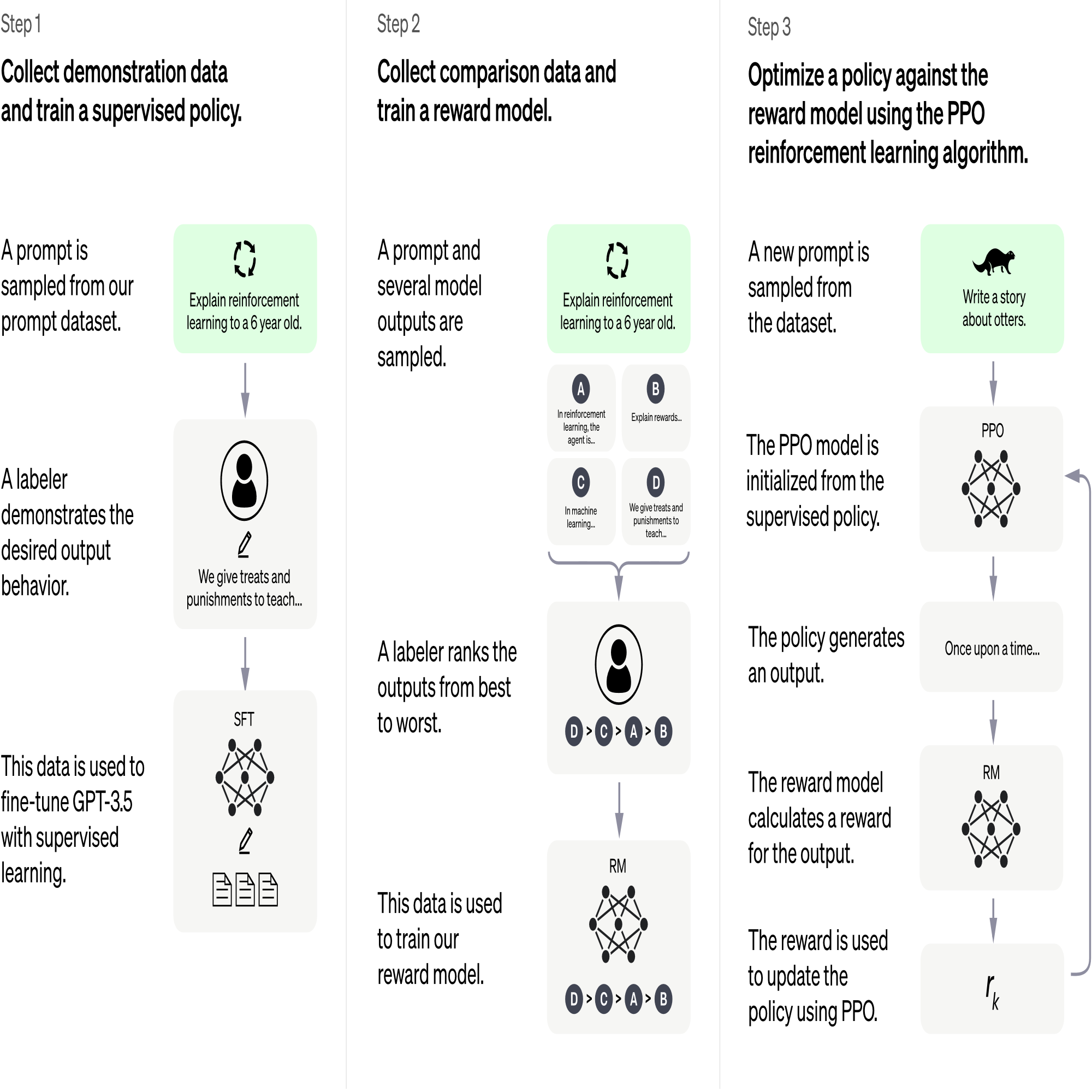
CHATGPT训练步骤
Self-Organizing Feature Map/Proximal Policy Optimization
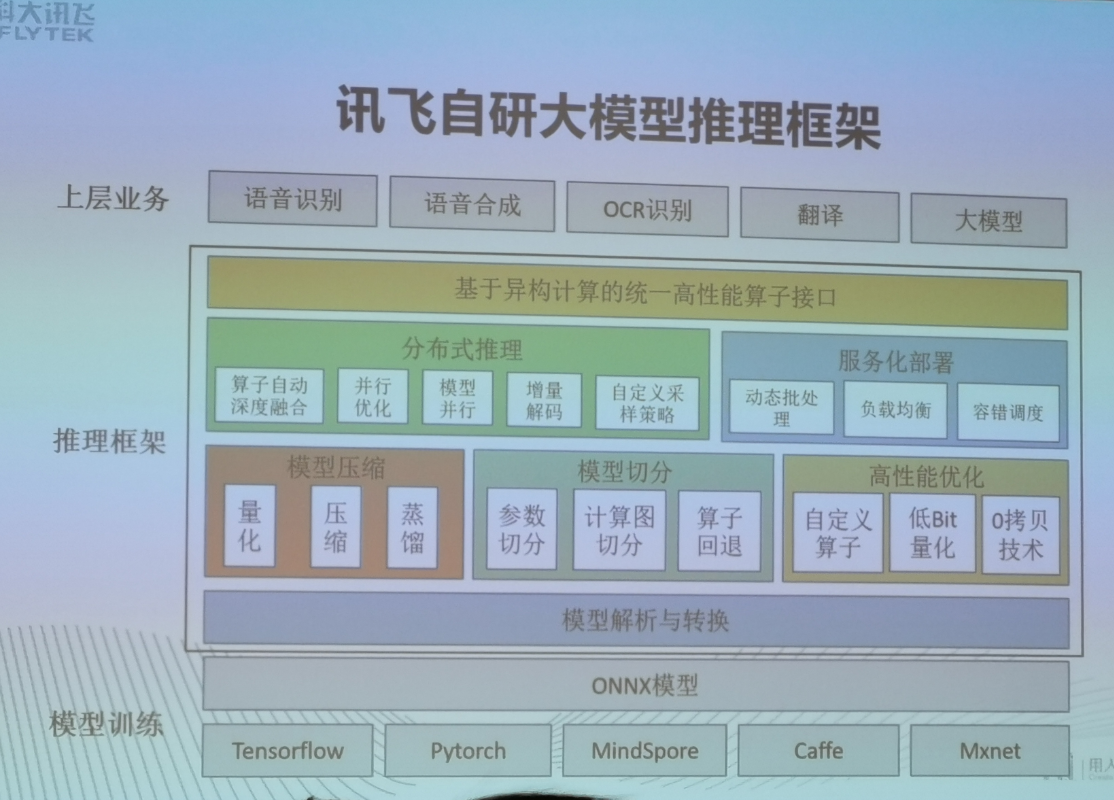

大模型训练关键优化技术总结
ZeRO1/2/3内存优化策略、重计算、3D并行、序列并行
高频算子优化:充分利用L1/L2 Cache提升Cube利用率
融合Kernel & Transformer加速库
高性能Kernel动态调度和下发
集合通信优化: SDMA&RDMA通信流水化及带宽复用
断点续训、按故障影响范围分级恢复,保障业务高可用
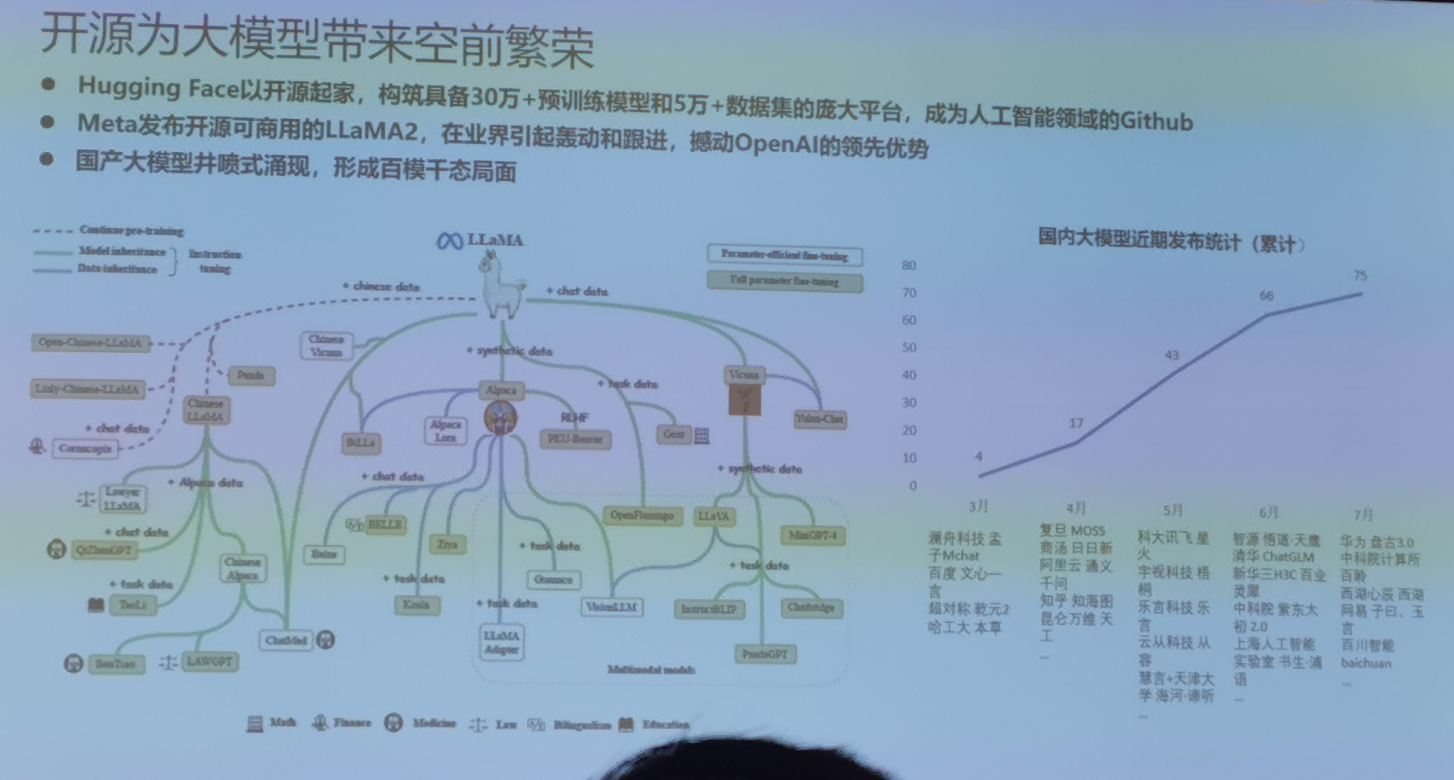

未来工作展望
1.面向在线服务的JCT job completion time) 的调度和batching优化, 缩短服务时延
2.基于计算图的weight预取与Cache驻留优化,提升访存性能
3.异腾亲和的FlashAttention2&业界最新融合算子实现, 提升计算性能
4.支持更丰富的量化计算组合、模型稀疏,降低内存占用